
Comment l’IA générative transforme les métiers de la recherche ?
Publications scientifiques, nouvelles pistes de recherche, évaluation des pairs… l’IA s’est désormais immiscée dans tous les pans de la recherche. Mais à quel prix ? Et comment en encadrer son utilisation exponentielle ?
Cet article est le troisième d’une série de cinq sur le futur de la recherche.
En 2024, le prix Nobel de chimie mettait l’intelligence artificielle à l’honneur en récompensant le biochimiste David Baker, ainsi que l’entrepreneur Demis Hassabis et le chimiste et informaticien John Jumper. Ces deux derniers ont créé un logiciel basé sur un modèle d’IA, nommé AlphaFold, qui a permis de « réaliser un rêve vieux de 50 ans : prédire les structures protéiques à partir de leurs séquences d’acides aminés », soulignait le président du Comité Nobel de chimie, Heiner Linke.
« Concrètement, AlphaFold s’appuie sur une immense base de données, la Protein Data Bank, afin d’établir un lien prédictif entre la séquence et la structure grâce à l’apprentissage profond, détaille Marc Baaden, directeur du Laboratoire de biochimie théorique1 . Avant l’arrivée d’AlphaFold, il fallait compter entre six mois et deux ans pour prédire la structure d’une protéine à partir de sa séquence et le taux de fiabilité était d’environ 20 à 30 %. Désormais, cela prend 10 minutes, et la fiabilité dépasse 90 % ». Un véritable changement de paradigme s’opère sous nos yeux. « L’un des effets collatéraux, c’est que cela a conduit à la démocratisation de cet exercice. Chaque expérimentateur devait auparavant faire appel à un expert pour réaliser cette tâche. Il est désormais possible d’effectuer la manipulation en quelques minutes sur AlphaFold. Cela change donc totalement la façon de travailler », poursuit Marc Baaden.
- 1CNRS/Université Paris Cité.
Nous sommes à l’aube d’un grand tournant dans le monde de la recherche : les outils d’IA permettent de repousser des limites auxquelles se sont heurtés les scientifiques pendant des décennies. « L’IA ne résoudra évidemment pas tous les problèmes, mais cela va ouvrir plein de possibilités et déboucher sur un grand nombre de questions intéressantes pour la science en automatisant de nombreuses tâches », détaille Liviu Stirbat, chef de l’unité « IA dans la science » au sein de la direction générale de la Recherche et de l’innovation de la Commission européenne. « Dans certains domaines particulièrement complexes, comme la physique ou la biologie, les espaces d’explorations sont tellement immenses qu’il est nécessaire de mobiliser des outils d’IA qui vont nous assister, souligne Jalal Fadili, chercheur au sein du Groupe de recherche en informatique, image, automatique et instrumentation de Caen1 et directeur du centre AI for science, science for AI (AISSAI), lancé par le CNRS en 2021. Mais pour cela, il faut pouvoir s’appuyer sur des données de très bonne qualité. Le travail sur la structuration et la curation des données afin de les rendre prêtes pour les outils d’IA est donc tout aussi important que celui qui est mené sur le développement des algorithmes ».
Forces et faiblesses des LLM
Les outils d’IA génératives, et notamment les grands modèles de langage – ou Large Language Model (LLM) – en anglais, occupent déjà une place importante dans les laboratoires. « Ils peuvent être utilisés afin de synthétiser un ensemble bibliographique sur un thème spécifique, ou encore pour l’assistance à la rédaction d’un papier scientifique », observe Floriana Gargiulo, chercheuse au Groupe d’étude des méthodes de l’analyse sociologique de la Sorbonne (Gemass)2 et coordinatrice du projet ANR « Applications et implications de l'intelligence artificielle dans la science – ScientIA ». « Ils sont aussi capables de prêter main-forte aux scientifiques en les aidant à formuler et à tester des hypothèses de recherche », ajoute Jalal Fadili. Les LLM sont particulièrement performants pour traduire des textes : « Pour des chercheurs qui ne seraient pas à l’aise avec l’anglais, des outils comme ChatGPT peuvent être d’une grande aide », remarque Marc Baaden. Ils sont également mobilisés pour certaines tâches spécifiques comme la programmation informatique, souligne Floriana Gargiulo : « Il suffit d’entrer les textes et les commentaires en langage humain pour que les outils d’IA produisent automatiquement les codes correspondants ». « Dans le cadre des grandes simulations multi-agents mobilisées en épidémiologie par exemple, l’IA peut générer des populations virtuelles. Cela peut s’avérer utile lorsqu’on ne bénéficie pas d’un accès détaillé aux données démographiques », poursuit la chercheuse.
Mais comment marchent ces outils ? « Le fonctionnement d’un LLM est basé sur le fait de prédire le prochain mot dans une phrase donnée, indique Antoine Houssard, doctorant en sciences sociales computationnelles au sein du Centre internet et société du CNRS et membre du projet ANR ScientIA. Concrètement, la machine utilise des textes et tente de prédire de nouveaux mots. Elle fait des erreurs, puis retente à de nombreuses reprises ce qui lui permet d’ajuster son modèle jusqu’à ce qu’il soit efficient ». Les LLM déployés aujourd’hui sont particulièrement performants : ils s’appuient sur les contextes, cela peut être un paragraphe ou même un texte entier, afin de générer des phrases complètes, des audios ou des images.
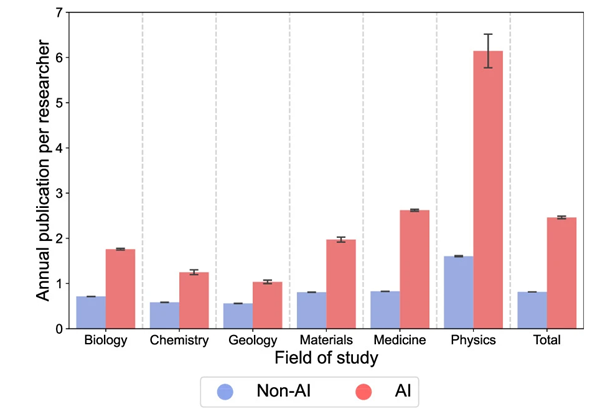
Néanmoins, ces outils d’IA peinent à sortir des sentiers battus. Une étude réalisée par une équipe de recherche internationale et publiée en janvier dernier dans la revue Nature a analysé 41 millions de publications scientifiques, dont 311 000 avaient été réalisées au moins en partie à l’aide d’un outil d’IA. Les auteurs de l’étude ont mis en évidence un étonnant paradoxe. Côté pile, les scientifiques qui s’appuient sur l’IA pour leurs recherches publient davantage, sont plus fréquemment cités que les autres et progressent plus rapidement dans leur carrière. Côté face, les recherches menées grâce à l’IA explorent moins de nouveaux territoires que les autres, et ont tendance à se cantonner aux champs d’études déjà bien établis. « Pour produire des recherches intéressantes, nous devons chercher à élargir nos connaissances. Or, les LLM produisent des probabilités. Ils vont donc avoir naturellement tendance à nous forcer à rester proches de trajectoires déjà explorées », souligne Floriana Gargiulo. « En réalité, on s’aperçoit que les outils d’IA parviennent surtout à faire ressortir des éléments ou des connexions qui étaient déjà présents dans la masse de données disponibles, mais que les humains n’avaient pas remarqués jusqu’alors », complète Liviu Stirbat.
Une avalanche de publications sous IA
Un autre risque pour la communauté scientifique serait d’être ensevelie sous une avalanche de publications, réalisées en partie ou en totalité grâce aux IA. Les gains de productivité liés à l’utilisation des LLM dans la recherche sont spectaculaires : ils pourraient s’élever à plus de 89 %, selon une étude publiée en décembre dernier dans la revue Science. « Nous constatons que l’IA tend à être de moins en moins performante lorsque les tâches se complexifient. Le risque est de se retrouver avec une production scientifique encore plus massive qu’elle ne l’est actuellement, mais avec des travaux de moindre qualité. Pour les chercheurs, il sera difficile de faire le tri dans cette masse informationnelle », s’inquiète Antoine Houssard. « Des outils sont actuellement développés par les scientifiques afin de repérer les publications peu rigoureuses générées par l’IA. Je pense qu’à terme, nous aurons quand même les moyens de distinguer celles qui posent problème », tempère Sylvain Fontaine, chercheur au Gemass.
Cependant, nous sommes confrontés à un autre dilemme lié à l’usage de l’IA dans la recherche. L’explosion exponentielle du nombre de publications conduit à une véritable « crise de l’évaluation par les pairs ». La quantité de publications indexées dans Scopus et Web of Science, les principales bases de données bibliographiques – dont le CNRS s’est désabonné respectivement en 2024 et 2026 –, a augmenté de 47 % entre 2016 et 2022, pointe une autre étude publiée dans la revue Quantitative Science Studies. « Le nombre d’articles qu’il faudrait relire chaque année dépasse largement le nombre d’heures que les différents relecteurs peuvent y consacrer », observe Marc Baaden. Certains relecteurs misent alors sur l’IA pour absorber le flot de publications qu’ils reçoivent. « Il est certain que des outils d’IA sont déjà mobilisés pour faire de la relecture qui est censée être effectuée par les pairs. Plusieurs de mes collègues ont déjà été confrontés à cela. Ils ont notamment repéré la présence de références à des articles inexistants, entièrement inventés par l’IA, souligne Marc Baaden. Et ce n’est clairement pas une bonne pratique car les IA ne peuvent en aucun cas avoir autant de discernement qu’un relecteur qui connait bien le domaine en question. La richesse d’une bonne relecture réside dans le fait que l’expert essaie d’aider les auteurs à produire un article de la meilleure qualité possible ». « Les LLM ont très souvent un biais de positivité. Ils sont calibrés de manière à favoriser l’engagement des utilisateurs et pourraient donc clairement laisser passer des productions qui sont de manière évidente plutôt mauvaises », ajoute Antoine Houssard. En outre, « l’IA ne sera pas efficace pour valider des papiers qui traitent de recherches réellement innovantes, car elle considérerait cette recherche comme étant trop éloignée des domaines déjà explorés », souligne Floriana Gargiulo. A l’heure où nous traversons une crise de confiance d’une partie de la population vis-à-vis des travaux scientifiques et de leurs résultats, « il est impératif de garder l’humain dans la boucle afin de ne pas se faire submerger par des publications de mauvaise qualité », avertit Liviu Stirbat.
Vers une IA frugale et responsable
Dans ce contexte, les autorités tentent de légiférer afin de poser un cadre clair permettant d’encadrer ces usages. « Les outils d’IA peuvent apporter des avantages indéniables pour la recherche scientifique car ils sont très puissants, mais il est absolument nécessaire de s’en saisir de manière responsable », souligne Liviu Stirbat. Pour cela, la Commission européenne a publié en 2024 un premier guide d’utilisation de l’IA à destination des acteurs et des actrices du monde de la recherche intitulé : « Lignes directrices sur l'utilisation responsable de l'IA générative dans la recherche ». Il y est notamment stipulé que « les chercheurs et les chercheuses s'abstiennent d'utiliser des outils d'IA générative dans des activités sensibles telles que les évaluations par les pairs et utilisent l'IA générative en respectant la vie privée, la confidentialité et les droits de propriété intellectuelle ». « Cela permet à la fois de préparer les scientifiques à utiliser ces outils d’IA, mais aussi de les rassurer et de leur donner des outils d’éthique et d’intégrité », précise le représentant européen.
Néanmoins, l’utilisation de l’IA au service de la recherche soulève encore de nombreuses inquiétudes, notamment au niveau de l’impact environnemental généré par l’usage de plus en plus massif de ces outils. « On ne peut pas raisonnablement se satisfaire de modèles immenses qui mobilisent de grandes quantités d’énergie pour des requêtes qui, la plupart du temps, ne servent strictement à rien. Je pense que nous devrons nous orienter vers des IA de plus en plus spécialisées en fonction des disciplines, et pour chaque tâche », souligne Jalal Fadili. « Cet enjeu de frugalité est très important, et nous travaillons activement là-dessus au CNRS », conclut le directeur du centre AISSAI.
